股票量化交易策略最基本有两种形式,趋势交易和市场中性,经常使用的方法为多因子选股和趋势追踪
注:不管是趋势追踪策略还是多因子选股策略,都是为了获取一定的超额收益。趋势追踪策略通过各种交易时机手段获取,而股票的多因子选股策略则是通过选股获得
收益到底从何而来?什么影响股票的收益?
Alpha和Beta
每个投资策略的收益率可以分解成为两部分:
一部分与市场完全相关,整个市场的平均收益率乘以一个贝塔系数。贝塔可以称为这个投资组合的系统风险另一部分和整个市场无关的叫做阿尔法

Alpha很难得,Beta很容易。Alpha就是精选个股,跑赢市场。Beta就是有市场行情时跟上,有风险时候躲避
什么是多因子选股策略
多因子选股策略是一种应用十分广泛的选股策略,其基本思想就是找到某些和收益率最相关的因子。
多因子的种类
按照因子分析的角度
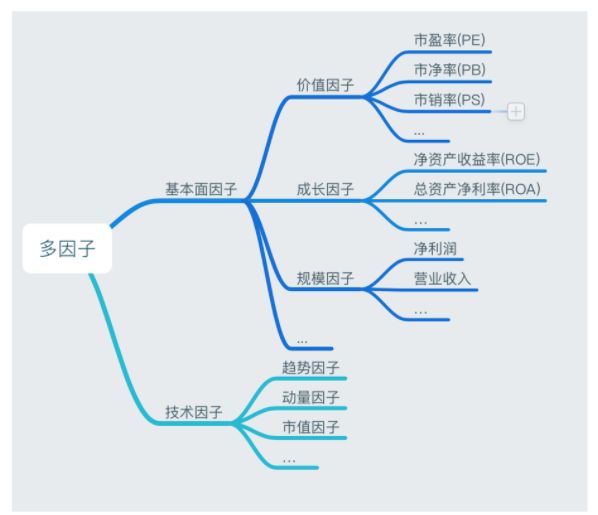
基本面因子价值因子盈利因子成长因子资本结构因子运营因子流通性因子技术因子动量因子趋势因子市值因子波动因子成交量因子按照因子来源的角度
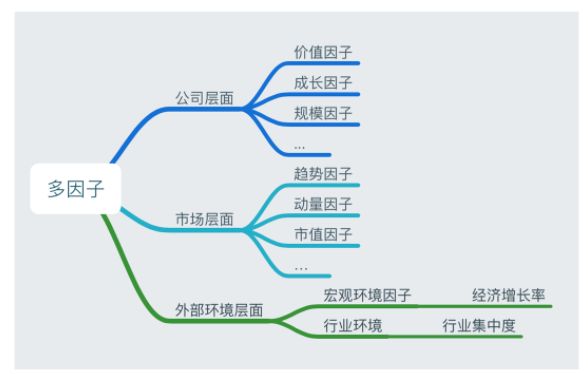
公司层面价值因子成长因子规模因子等市场层面趋势因子动量因子市值因子外部环境层面宏观环境行业环境
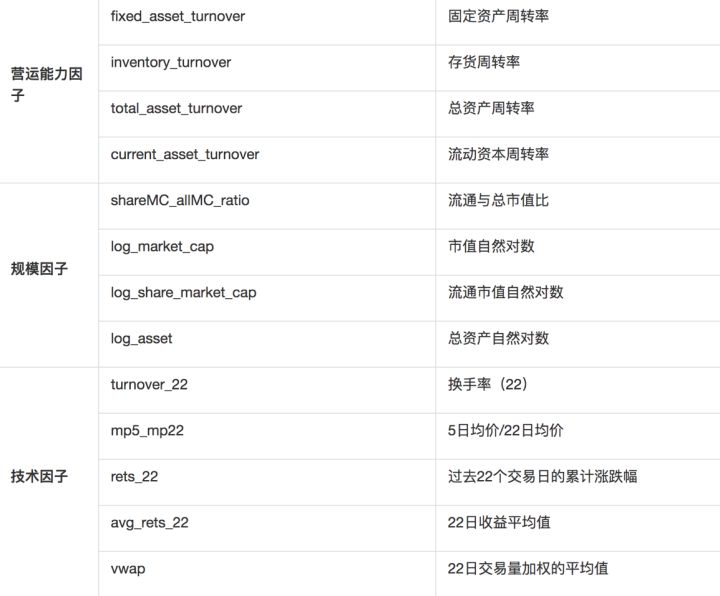
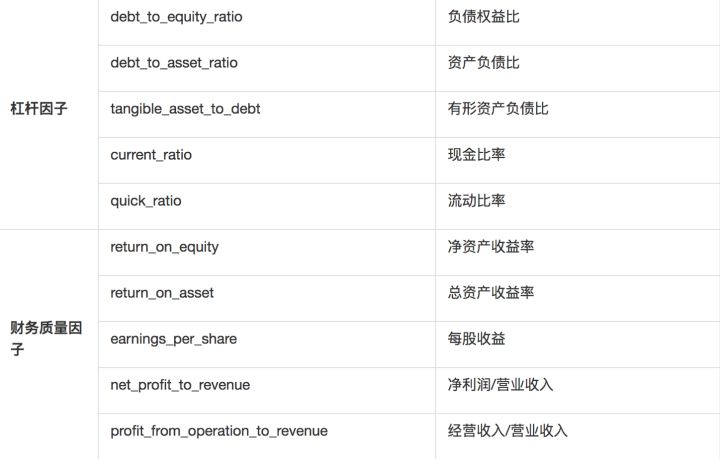
大类因子细分
多因子策略的优势
多元因子,阿尔法收益的来源丰富,多因子持续稳定根据市场环境的变化选取最优因子和权重,模型可修改
多因子策略的理论来源?什么影响股票的收益率?
资产定价模型
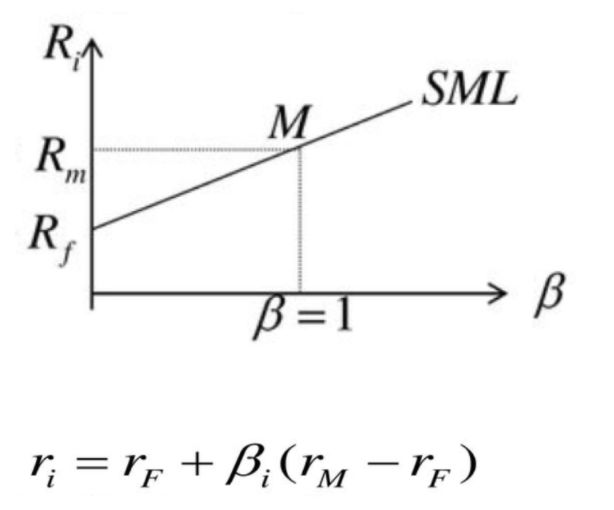
ri:证券的收益率rF:无风险利率rM:市场收益率rM-rF:风险溢价β:某个公司与市场的相关性
这个模型可以理解为单因子模型-系统风险,我们的收益只跟市场走。
套利定价理论
假设证券收益率与一组未知因子线性相关
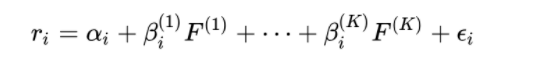
APT模型其实就是相当于一个多因子模型,证券收益通过权重系数回归得到。但是并没有指出其中具体的因子是什么
FF三因子模型
Fama和French1992年对美国股票市场决定不同股票回报率差异的因素的研究发现,超额回报率可由它对三个因子来解释。市场资产组合、市值因子、账面市值比因子。
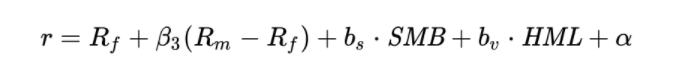
三因子模型指出了规模因子、价值因子。
发现市值较小、市值账面比较低的两类公司更有可能取得优于市场水平的平均回报率意味着那些市值较小的公司组成的投资组合,可以预期能带来更高的回报,与更高的风险。所以在2017年之前一段时间之内,大多数量化公司在市值小的指标进行筛选就能获取很高的回报
在过去20年里面,很多学者对三因子模型进行实证分析,发现有些股票的alpha显著不为0,这说明三因子模型中的三个风险并不能解释所有超额收益。
FF五因子模型
Fama和French发现在上述风险之外,还有盈利水平风险、投资水平风险也能带来个股的超额收益,并于2015年提出了五因子模型
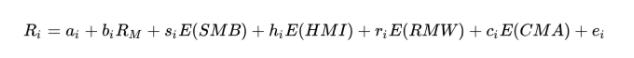
其实五因子模型就是增加了盈利因子和成长因子这两类因子
与三因子类似,参数估计的方法仍然是用多元线性回归的方法,这里的a_i则是五因子模型里面尚未解释的超额收益。
关于挖掘与怎么做
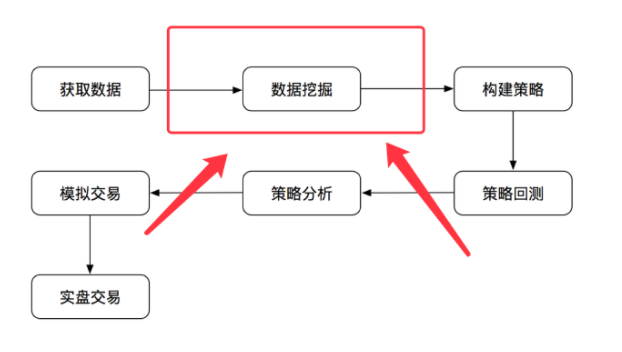

很多数据或者证券公司的研究报告当中,有很多一些新的方法可以去发掘
案例:市值因子的选股策略
1结果
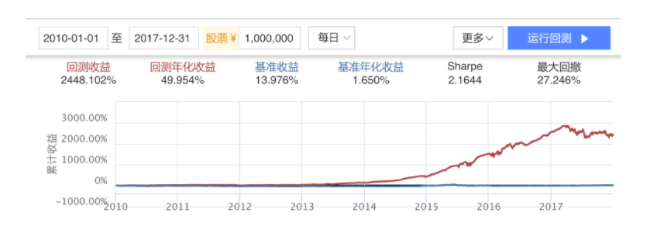
2从市值中选择值小的股票
选定财务数据筛选进行每日调仓
3代码
def init(context):
context.limit = 20
def before_trading(context):
# 获取财务数据中的市值,然后按照市值大小排序
fund = get_fundamentals(
query(
fundamentals.eod_derivative_indicator.market_cap
).order_by(
fundamentals.eod_derivative_indicator.market_cap.asc()
).limit(
context.limit
)
)
# 将这20支股票的代号
context.stocks = fund.columns
def handle_bar(context, bar_dict):
# 先得出投资组合当中的仓位有没有股票,注意这里的仓位即使为0,但是
# 股票名字还在
holding = []
for stock in context.portfolio.positions.keys():
# 判断当前的股票是否有持有股份
if context.portfolio.positions[stock].quantity > 0:
holding.append(stock)
# 判断哪些要卖出去,哪些要买入
to_sell = set(holding) - set(context.stocks)
to_buy = context.stocks
# 进行买卖判断
for sell in to_sell:
order_target_percent(sell, 0)
# 购买的比例
percent = 1.0 / len(to_buy)
for buy in to_buy:
order_target_percent(buy, percent)多因子策略流程
多因子策略流程
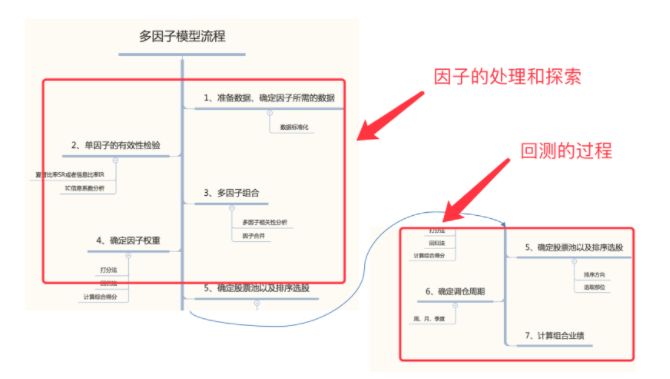
重在因子的探索和处理
我们可以得出以下步骤
因子挖掘因子数据的处理去极值标准化中性化单因子的有效性检测因子IC分析因子收益率分析因子的方向多因子相关性和和组合分析因子相关性因子合成回测多因子选股的权重调仓周期
多因子策略确定的事情
选择哪些因子和因子的方向确定因子的权重调仓周期
其中1步骤属于因子的探索和处理部分,2和3步骤属于选好因子回测部分
因子挖掘怎么做?
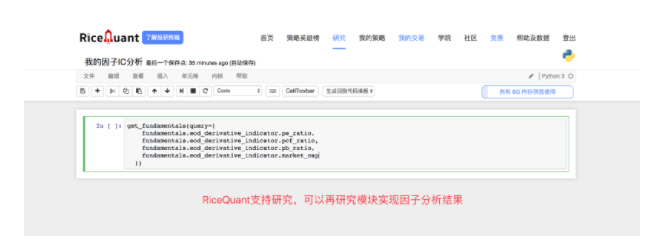
由于此部分不是回测,所以我们需要在单独的研究平台使用特定的接口进行分析。RQ平台提供了这样的研究平台供我们去挖掘因子
关于研究平台的获取函数
在研究因子的时候我们需要获取更多区间段历史的数据来进行研究,所以研究平台当中的函数会跟回测中不一样
1get_price-获取合约历史数据
get_price(order_book_id, start_date="2013-01-04", end_date="2014-01-04", frequency="1d", fields=None, adjust_type="pre", skip_suspended =False, country="cn")获取指定合约或合约列表的历史数据。目前仅支持中国市场。在编写策略的时候推荐使用history_bars
| 参数 | 类型 | 说明 |
|---|---|---|
| order_book_id | str OR str list | 合约代码,可传入order_book_id, order_book_id list |
| start_date | str, datetime.date, datetime.datetime, pandasTimestamp | 开始日期,默认为"2013-01-04"。交易使用时,用户必须指定 |
| end_date | str, datetime.date, datetime.datetime, pandasTimestamp | 结束日期,默认为"2014-01-04"。交易使用时,默认为策略当前日期前一天 |
| frequency | str | 历史数据的频率。 现在支持日/分钟级别的历史数据,默认为"1d"。使用者可自由选取不同频率,例如"5m"代表5分钟线 |
| fields | str OR str list | 返回字段名称 |
| adjust_type | str | 前复权处理。前复权 - pre,后复权 - post,不复权 - none,回测使用 - internal需要注意,internal数据与回测所使用数据保持一致,仅就拆分事件对价格以及成交量进行了前复权处理,并未考虑分红派息对于股价的影响。所以在分红前后,价格会出现跳跃。 |
| skip_suspended | bool | 是否跳过停牌数据。默认为False,不跳过,用停牌前数据进行补齐。True则为跳过停牌期。注意,当设置为True时,函数order_book_id只支持单个合约传入 |
| country | str | 默认是中国市场("cn"),目前仅支持中国市场 |
传入一个order_book_id,多个fields,函数会返回pandasDataFrame传入一个order_book_id,一个field,函数会返回pandasSeries传入多个order_book_id,一个field,函数会返回pandasDataFrame传入多个order_book_id,函数会返回pandasPanel
案例:
获取单一股票历史日线行情:
[In]get_price("000001.XSHE", start_date="2015-04-01", end_date="2015-04-12")
[Out]
open close high low total_turnover volume limit_up limit_down
2015-04-01 10.7300 10.8249 10.9470 10.5469 2.608977e+09 236637563.0 11.7542 9.6177
2015-04-02 10.9131 10.7164 10.9470 10.5943 2.222671e+09 202440588.0 11.9102 9.7397
2015-04-03 10.6486 10.7503 10.8114 10.5876 2.262844e+09 206631550.0 11.7881 9.6448
2015-04-07 10.9538 11.4015 11.5032 10.9538 4.898119e+09 426308008.0 11.8288 9.6787
2015-04-08 11.4829 12.1543 12.2628 11.2929 5.784459e+09 485517069.0 12.5409 10.2620
2015-04-09 12.1747 12.2086 12.9208 12.0255 5.794632e+09 456921108.0 13.3684 10.9403
2015-04-10 12.2086 13.4294 13.4294 12.1069 6.339649e+09 480990210.0 13.4294 10.9877获取股票列表历史日线收盘价:
[In]get_price(["000024.XSHE", "000001.XSHE", "000002.XSHE"], start_date="2015-04-01", end_date="2015-04-12", fields="close")
[Out]
000024.XSHE 000001.XSHE 000002.XSHE
2015-04-01 32.1251 10.8249 12.7398
2015-04-02 31.6400 10.7164 12.6191
2015-04-03 31.6400 10.7503 12.4891
2015-04-07 31.6400 11.4015 12.7398
2015-04-08 31.6400 12.1543 12.8327``
2015-04-09 31.6400 12.2086 13.5941
2015-04-10 31.6400 13.4294 13.2969获取股票列表历史日线行情:
[In]get_price(["000024.XSHE", "000001.XSHE", "000002.XSHE"], start_date="2015-04-01", end_date="2015-04-12")
[Out]
<class "rqcommons.pandas_patch.HybridDataPanel">
Dimensions: 8 (items) x 7 (major_axis) x 3 (minor_axis)
Items axis: open to limit_down
Major_axis axis: 2015-04-01 00:00:00 to 2015-04-10 00:00:00
Minor_axis axis: 000024.XSHE to 000002.XSHE2get_trading_dates-获取交易日列表
get_trading_dates(start_date, end_date, country="cn")获取某个国家市场的交易日列表。目前仅支持中国市场。
| 参数 | 类型 | 说明 |
|---|---|---|
| start_date | str, datetime.date, datetime.datetime, pandasTimestamp | 开始日期 |
| end_date | str, datetime.date, datetime.datetime, pandasTimestamp | 结束日期 |
| country | str | 默认是中国市场("cn"),目前仅支持中国市场 |
datetime.datelist-交易日期列表
[In]get_trading_dates(start_date="20160505", end_date="20160505")
[Out]
[datetime.date(2016, 5, 5)]3get_fundamentals-查询财务数据
get_fundamentals(query, entry_date, interval=None, report_quarter=False)使用get_fundamentals查询财务数据时,我们是以所有年报的发布日期为准,因为只有财报发布后才成为市场上公开可以获取的数据。比如某公司第三季度的财报于11月10号发布,那么如果从查询日期为10月5号,也就是早于发布日期,那么返回的只是第二季度的财报数据。如需获取固定报告期的财务数据请使用get_financials。
pandasDataPanel-财务数据查询结果。
fundamentals是一个重要的对象,其中包括了股指指标表,财务指标表,利润表,资产负债表,现金流量表以及股票列表等内容。结合SQLAlchemy的查找方式,能够满足用户多种查找需求。
获取某几只股票2015年1月10日及以前5年的营业收入以及营业成本
[In]dp = get_fundamentals(query(fundamentals.income_statement.revenue, fundamentals.income_statement.cost_of_goods_sold
).filter(fundamentals.income_statement.stockcode.in_(["002478.XSHE", "000151.XSHE"])), "2015-01-10", "5y")
[In]dp
[Out]
<class "pandas.core.panel.Panel">
Dimensions: 2 (items) x 5 (major_axis) x 2 (minor_axis)
Items axis: revenue to cost_of_goods_sold
Major_axis axis: 2015-01-09 to 2011-01-10
Minor_axis axis: 002478.XSHE to 000151.XSHE
[In]dp["revenue"]
[Out]
002478.XSHE 000151.XSHE
2015-01-09 2.937843e+09 1.733703e+09
2014-01-10 2.926316e+09 8.839355e+08
2013-01-10 2.616532e+09 9.488980e+08
2012-01-10 2.681016e+09 6.205934e+08
2011-01-10 2.034147e+09 4.998120e+08因子数据处理-去极值
学习目标
目标说明面板数据、序列数据和截面数据的区别知道处理因子数据是对每个因子的截面数据进行处理了解分位数的作用应用分位数去极值实现分位数去极值了解中位数绝对偏差法实现中位数绝对偏差法去极值了解3倍sigma法则实现3倍sigma法去极值比较三种去极值方法优缺点应用无
那么在多因子策略当中,我们分析因子的数据是怎么组成的?因子跟收益率的分析,应该是怎么样的结构提供?
因子Panel结构分析
Pandas当中的面板数据结构是为了存储三维的结构。由截面数据和序列数据组成
1截面数据
横截面数据:在同一时间,不同统计单位相同统计指标组成的数据列

2序列数据
序列数据:在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度

多因子分析使用的是截面数据!!!
什么是因子去极值处理
去极值并不是删除”异常数据”,而是将这些数据”拉回”到正常的值
注:极值可以理解离群值或者异常数据
1三种方法
分位数去极值中位数绝对偏差去极值正态分布去极值
之前在接触一些统计指标的时候,知道最大最小值、平均值、方差、标准差等等。那么这里我们使用一种叫分位数的指标来进行去极值
分位数去极值
中位数四分位数百分位数
1中位数
定义:中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数用Me表示
14、15、16、16、17、18、18、19、19、20、2l、11、22、22、23、24、24、25、26
中位数为:20,如果不存在中间的一个数,那么取中间的两个数平均值为什么需要中位数这种指标
比如现在有四个人,A年收入12万,B年收入10万,C年收入9万,D年收入10亿。那么我们去求这四个人的平均收入,这样每个人收入都过亿了,明显不准确。所以假设我们来求中位数反应他们的平均收入,先从小到大排列,9,10,12,10亿,这样取中位数,10+12/2 = 11万,这个结果才反应了大家的平均水平。所以有时候很多地区在统计平均薪资的时候,感觉到被平均,是因为平均值结果并不理想。2四分位数
即把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数

第一四分位数,又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。第二四分位数,又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。第三四分位数,又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
有一个四分位数计算的案例:http://wiki.mbalib.com/wiki/%E5%9B%9B%E5%88%86%E4%BD%8D%E6%95%B0
3百分位数
前面的中位数,四分位数都是一些特例。百分位数即数据所处位置为整体的某个%位数。关于百分位数有两种称呼,quantile和percentile。他们之间的关系如下
0 quantile = 0 percentile
0.25 quantile = 25 percentile
0.5 quantile = 50 percentile
0.75 quantile = 75 percentile
1 quantile = 100 percentile4分位数去极值
1原理
将指定分位数区间以外的极值用分位点的值替换掉
fromscipy.stats.mstatsimportwinsorizescipy.stats.mstats.winsorizeReturnsaWinsorizedversionoftheinputarrayParameters:a:sequenceInputarray.limits:float数据两端的percentile的值
5案例:对pe_ratio进行去极值
1结果现象
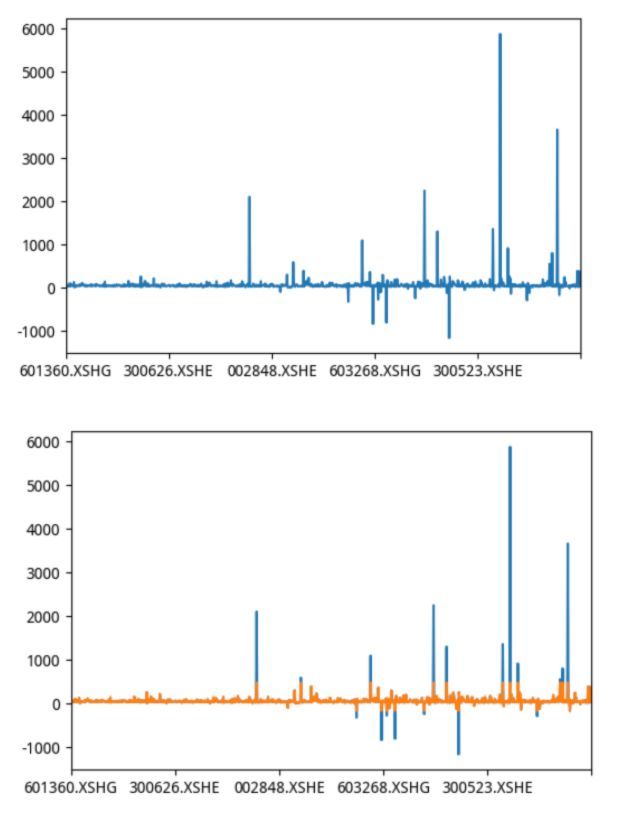
2分析
获取指定某个日期或者区间段的pe_ratio的截面数据分位数去极值去极值结果与去极值前结果比较
3代码
# 获取财务必须填写日期
factor = get_fundamentals(query(fundamentals.eod_derivative_indicator.pe_ratio), entry_date="20180103")[:, 0, :]
factor["pe_ratio"][:1000].plot()
# 百分位去极值
# 将2.5%分位数以下的值,替换
# 将97.5%分位数以上的值,替换
factor["pe_ratio1"] = winsorize(factor["pe_ratio"], limits=0.025)
factor["pe_ratio"][:1000].plot()
factor["pe_ratio1"][:1000].plot()6自实现分位数去极值
# 求出两个分位数的点的值
def quantile(factor,up,down):
"""分位数去极值 """
up_scale = np.percentile(factor, up)
down_scale = np.percentile(factor, down)
factor = np.where(factor > up_scale, up_scale, factor)
factor = np.where(factor < down_scale, down_scale, factor)
return factor中位数绝对偏差去极值
MAD又称为中位数绝对偏差法,MAD是一种先需计算所有因子与中位数之间的距离总和来检测离群值的方法。
1计算方法
找出因子的中位数median得到每个因子值与中位数的绝对偏差值|x–median|得到绝对偏差值的中位数,MAD,median计算MAD_e=4826*MAD,然后确定参数n,做出调整
去除极值判断:
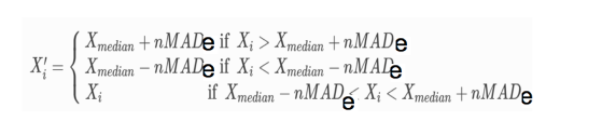
注:通常把偏离中位数三倍MAD_e,如果样本满足正态分布,且数据量较大,可以证明以上的数据作为异常值。和均值标准差方法比,中位数和MAD的计算不受极端异常值的影响,结果更加稳健。
2实现中位数绝对偏差法
def mad(factor):
"""3倍中位数去极值
"""
# 求出因子值的中位数
med = np.median(factor)
# 求出因子值与中位数的差值,进行绝对值
mad = np.median(abs(factor - med))
# 定义几倍的中位数上下限
high = med + (3 * 1.4826 * mad)
low = med - (3 * 1.4826 * mad)
# 替换上下限以外的值
factor = np.where(factor > high, high, factor)
factor = np.where(factor < low, low, factor)
return factor3案例:对pe_ratio进行去极值
1结果
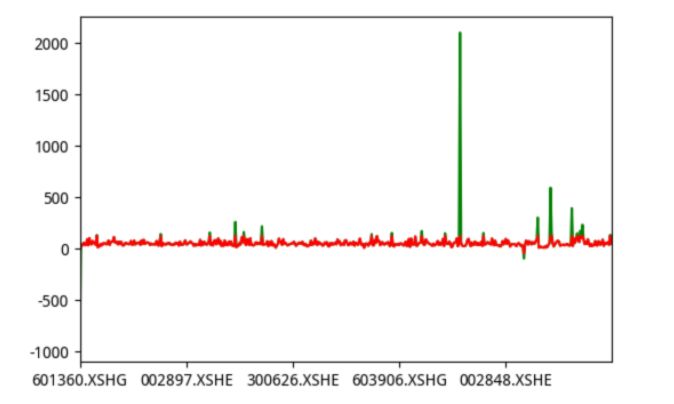
2分析
中位数绝对偏差去极值去极值结果与去极值前结果比较
3代码
# 进行中位数去极值
factor["pe_ratio2"] = mad(factor["pe_ratio"])
# 显示
factor["pe_ratio"][:500].plot(color="g")
factor["pe_ratio2"][:500].plot(color="r")正态分布去极值
3sigma原则
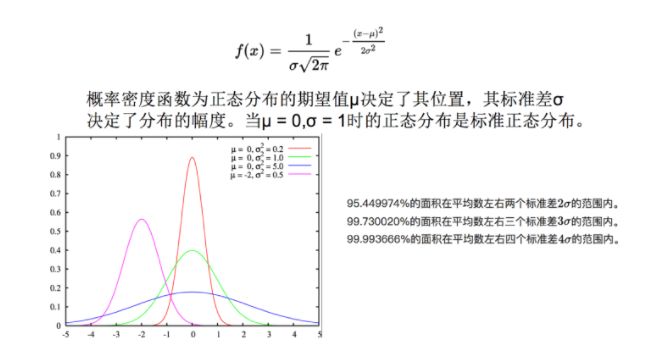
13sigma方法实现
# 3sigma原则
def three_sigma(factor):
# 求出因子数据的平均值和标准差
mean = factor.mean()
std = factor.std()
# 左右的数据加减3个标准差
high = mean + (0.01 * std)
low = mean - (0.01 * std)
# 替换极值数据
factor = np.where(factor > high, high, factor)
factor = np.where(factor < low, low, factor)
return factor2案例:对pe_ratio进行去极值
1结果
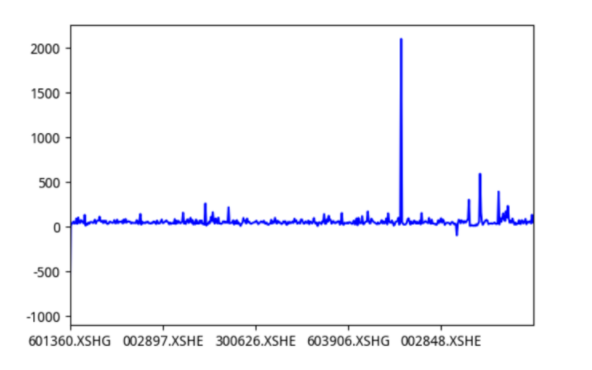
2分析
3sigma方法去极值去极值结果与去极值前结果比较
3代码
# 进行中位数去极值
factor["pe_ratio3"] = three_sigma(factor["pe_ratio"])
factor["pe_ratio"][:500].plot(color="g")
factor["pe_ratio3"][:500].plot(color="r")因子数据处理-标准化
对pe_ratio标准化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
std.fit_transform(factor["pe_ratio2"])实现标准化
在调用fit_transform之后,数据的类型会变成array数组。不去修改原来的类型,我们可以简单的实现
def stand(factor):
"""自实现标准化
"""
mean = factor.mean()
std = factor.std()
return (factor - mean)/stdfactor["pb_ratio"] = stand(factor["pb_ratio"])因子数据处理-市值中性化
为什么需要中性化处理?什么时候用?
市值中性化是为了在因子选股回测的时候防止选到的股票集中在固定的某些股票当中。
怎么理解?
1市值影响
默认大部分因子当中都包含了市值的影响,所以当我们通过一些指标选择股票的时候,每个因子都会提供市值的因素,是的选择的股票比较集中,也就是选股的标准不太好。
比如:市净率会与市值有很高的相关性,这时如果我们使用未进行市值中性化的市净率,选股的结果会比较集中。
怎么去除市值影响
我们结合之前的算法或者知识点,那个方法可以去除一个因子对另一个因子的影响?

市场中性化处理-回归法
在每个时间截面上用所有股票的数据做横截面回归方程,x为市值因子,y为要去除市值影响的因子

通过拟合找到x,y的关系公式,预测的时候会出现偏差?这个偏差是什么?
这个偏差即为保留下来的某因子除去市值影响的部分
回归法API
fromsklearn.linear_modelimportLinearRegression把市值设置成特征,市值不进行任何处理将其它因子设置成目标值
案例:去除市净率与市值之间的联系部分
1分析
获取两个因子数据对目标值因子-市净率进行去极值、标准化处理建立市值与市净率回归方程通过回归系数,预测新的因子结果y_predict求出市净率与y_predict的偏差即为新的因子值
2代码
# 1、获取这两个因子数据
q = query(fundamentals.eod_derivative_indicator.pb_ratio,
fundamentals.eod_derivative_indicator.market_cap)
# 获取的是某一天的横截面数据
factor = get_fundamentals(q, entry_date="2018-01-03")[:, 0, :]
# 先对pb_ratio进行去极值标准化处理
factor["pb_ratio"] = mad(factor["pb_ratio"])
factor["pb_ratio"] = stand(factor["pb_ratio"])
# 确定回归的数据
# x:市值
# y : 因子数据
x = factor["market_cap"].reshape(-1, 1)
y = factor["pb_ratio"]
# 建立回归方程并预测
lr = LinearRegression()
lr.fit(x, y)
y_predict = lr.predict(x)
# 去除线性的关系,留下误差作为该因子的值
factor["pb_ratio"] = y - y_predict
文章为作者独立观点,不代表股票交易接口观点
股民评论