数据挖掘是从数据库中发现知识的技术。它是针对知识获取的困难和不确定性而提出来的,可以自动地从海量数据中挖掘出知识,具体的知识获取过程借助机器学习的通达信接口支持交易吗,通达信接口支持交易吗,算法来实现。数据挖掘技术是一种通过自动或半自动的方式,从大规模数据集中发现有用的模式、关联、趋势和信息的过程。它结合了统计学、机器学习、人工智能和数据库技术,可以应用于各种领域,包括业务、科学、医疗、金融等,用于发现数据中的模式、预测未来趋势、进行分类和聚类分析、识别异常行为等。它可以帮助人们更好地理解数据,作出更准确的决策,并发现隐藏在数据背后的洞察和机会。常见的数据挖掘技术包括聚类分析、分类和预测、关联规则挖掘、异常检测等。这些技术通常通过使用通达信接口支持交易吗,通达信接口支持交易吗,算法和模型来处理和分析大量的数据,从中提取有用的信息,并生成可解释的结果。旨在提取出隐藏在数据中的有价值的知识。
C5算法优缺点
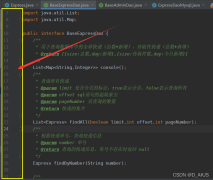
C5系列根据“信息增加的比值”来决定整个决策树的生成。具体上,信息增加值的计算过程如下:假设有一训练数据集S.它的任意一样品s隶属于类别Cj.数据集S的平均信息量根据下式计算:


数据挖掘技术可以通过分析大规模的遥感数据,自动提取出有效的特征或选择最具代表性的特征,以用于分类任务,帮助识别出对分类任务最具区分度的遥感指标或特征,从而提高分类模型的准确性和效率。基于已有的遥感数据集,利用包括支持向量机、随机森林、人工神经网络等的分类算法构建分类模型。通过训练模型并对其进行优化,实现遥感像的自动分类和识别。帮助分析和预处理遥感数据集,包括数据清洗、去噪、归一化等步骤。这些步骤可以提高数据的质量和准确性,为后续的分类任务提供更可靠的数据基础。通过交叉验证、混淆矩阵、精确度、召回率等指标来评估和验证分类模型的性能,有助于确定分类模型的准确性和可靠性,从而对遥感像进行准确的分类和识别。
C5算法的优点包括:·能处理多分类问题。·能处理离散型和连续型属性。·能处理缺失数据。·生成的决策树易于理解和解释。
为了防止产生过多的分解数目,要用splitinfo进行标准化.Splitinfo的计算如下:

C5算法
C5算法是一种经典的数据挖掘算法,用于构建决策树模型。它是由RossQuinlan于1993年提出的基于ID3算法的改进版本。它主要用于分类问题,通过对数据集进行递归划分,构建一个具有分支的决策树模型。其核心思想是选择最优的划分属性,使得划分后的子集尽可能地纯净,即同一类别的样本尽可能聚集在一起。C5算法的具体步骤如下:选择最优划分属性:通过计算各个属性的信息增益比,选择信息增益比最大的属性作为划分属性。根据划分属性的取值将数据集划分为不同的子集。对每个子集递归地应用上述步骤,构建决策树的子树。当满足终止条件时,停止递归构建决策树。常见的终止条件包括所有样本属于同一类别、没有可用的属性划分、达到预定的树深度等。根据构建的决策树模型,对新样本进行分类。
遥感专家系统分类中数据挖掘技术的应用:
当分解的数目过多时,分解的子集中,样本数目过少,同一分解子集中的类别区分数量更少的情况更加可能发生,同一分解子集中的同一类别样品数量占子集中总的样本数量的比值较大,导致单个子集的平均信息量较小,进而导致分解后的平均信息量,与分解前的平均信息量相比较,有很大出入导致分解后的信息增加值远远大于合理值。
数据集S的平均信息量,实质上是以2为底的对数函数在0到1的区间范围内离散类型的点对应的自变量和因变量之间的乘积之和,即S的类别数目个矩形的面积之和,从公式中我们可以通过画以及推导,当某一类别中样品数大于训练数据集总数的一半时,其对平均信息量的贡献值小于当某一类别中样品数小于训练数据集总数的一半时,其对平均信息量的贡献值大于当训练数据集中的分类数量多时,平均信息熵大,数据的不确定性或信息量更大;分类数量少时,平均信息熵小,数据的不确定性或信息量更小。其中freq为S中属于类别Cj的样品数目,|S|为样品总数目。假设把S分解为n个Si的子集,则分解后的平均信息量为分解后信息增加值为:





对此处标准化的理解可以认为,在分解子集数目过多的情况下,将远超合理值的信息增加量通过除以一个与自己相较更大的数值拉回到合理范围内,达到标准化的目的。

总体而言,C5算法是一种经典的决策树算法,在数据挖掘领域得到广泛应用,尤其适用于中小规模的分类问题。
最后有:

分解过程中,这里留个心眼,分解规则我认为在一些情况下是必要明确知道的。因为分解后的不同子集中,类别的数目以及同个类别内的数目之间的差异,对于分解后的平均信息量的数值会有影响,从而对于分解后的信息增加值也会产生影响。
文章为作者独立观点,不代表股票交易接口观点

股民评论