【目的】基于知识关联的研究视角构建领域知识谱发现行业特征和相关股票,为投资者的组合交易决策提供新的视角和依据。【方法】首先构建以股票数据为核心的种子知识谱,对非结构化的文本数据基于FinBERT预训练模型进行实体抽取和关系分类形成三元组,并将二者进行知识融合完成金融证券知识谱构建;然后基于谱利用链路预测、相似度计算等数据挖掘算法发现相关股票及其隐含特征,并通过统计学方法进行初步验证。【结果】构建了具有111845个实体和163370个关系的金融证券知识谱,基于谱分析了与“东北证券”相似度最高的10支跨行业相关股票,并结合“四环生物”案例分析股票间潜在的非线性相关关系。【局限】所构建的知识谱仅考虑了所属行业、股东持股等静态信息对股票相关性的影响。【结论】金融证券领域知识谱的构建和相关股票发现为投资者制定有效的投资组合策略,为股票趋势预测提供强有力的分析思路和数据支持。
关键词:知识关联;知识谱;金融证券;数据挖掘;股票发现
随着经济全球化进程的加速,全球经济与金融系统已经成为一个开放互联的关联复杂系统,股票、债券、期货、外汇、货币等子市场间的协同作用日益紧密。然而,从系统内数据要素的角度来看,当前各金融子市场内部及其之间的数据组织现状却依旧呈现出割裂、孤立的特点,严重阻碍了金融大数据和知识价值的分析、发现与利用,也使整个金融体系的协同发展与联动创新受到了影响。以证券投资领域为例,金融证券公司的主营业务繁杂,推行的相关投资产品种类丰富,服务对象也囊括各类大中企业、小微企业和个体,因而会产生海量的多源异构数据。这些数据具有多刻面、高稀疏性、分析结果经济效益明显直接等特点,因而对行业内知识组织与数据分析提出了更高的要求。目前,绝大多数投资行研分析仍依赖于人工对多源数据的集成和挖掘,效率低下的同时也难以发现潜藏在各类数据之间的关联知识。同样地,对于投资者,若要从海量信息中发现有助于投资决策的价值信息,需要用户具备专业的金融经济知识,并能够深刻理解某个数据的变动可能引发的关联及传导效应,这无疑大大增加了客户的认知成本,并提高了投资门槛。
2020年8月21日,中国证券业协会发布《关于推进证券行业数字化转型发展的研究报告》,强调依托人工智能、大数据等数字技术优化证券行业知识结构,推动证券行业数字化转型的重要性。其中,知识谱作为新一代人工智能的基石和重要技术工具之一,以其强大的语义处理能力和开放互联能力,可以充分保留关系复杂的语义信息,改变了传统金融知识组织和存储方式,并增加了跨金融系统和金融工具的数据互操作性,是对海量金融知识关联表示与高效存储的最佳技术支持。谱中呈现出的上市公司、人物、组织机构、行业、股票等多实体及其之间持股、交易、借贷等关系,既可以让相关从业人员更直观地了解和检索相关实体及关系信息,帮助其深刻理解数据变动带来的关联作用与传导效应;又能够为客户提供智能查询股票、行业、重仓概念板块和复杂股权关系等智能问答服务。此外,知识谱还能够基于领域间的关联知识,挖掘相关股票的多维特征,为投资者分析潜在的市场交易规律并进行理性决策提供新的可行思路与技术方案。已有的相关研究表明,与市场指数或行业指数相比,单一股票的价格波动更具非线性、动态性和混沌性,但多支股票之间的价格变动却存在一定的关联,这种价格波动关联的机理则是由多因素导致的[5,6]。对于投资者,利用知识谱发现相关股票并理清相关股票及其代表的企业或产业间的内在关联,对于构建证券投资产业链、制定有效的风险对冲投资组合决策具有重要意义。
2相关研究
知识谱是谷歌于2012年5月提出的概念,由本体作为Schema层,能够与RDF数据模型兼容的结构化数据集,其本质是语义网络的知识库。从知识组织的角度来说,知识谱可以被理解为一种开放的语义知识关联与服务技术。知识关联是指依托各种联系,如主题、事件、时空等,将非结构化的、零散的知识实现有序化的过程,是知识组织、管理与价值增值的重要环节。马费成认为知识组织的对象是知识单元与知识单元之间的逻辑关系,知识关联是一种技术维度,而知识谱本质上就是知识关联的一种技术实现方式。与链接数据相比,知识谱对数据质量的要求较高,同时能够提供面向终端用户的查询、问答等知识服务,具有更广泛的应用场景。
从金融知识谱的应用层面来看,目前学界和业界对于风险识别[20,21,22]和反欺诈[23,24,25]等方面的研究已趋于成熟,但在投资分析应用方面尚处于起步阶段。已有研究中,Liu等[26]聚焦于股票预测问题,基于知识谱嵌入的知识表示方法,实现了融合文本三元组信息的预测建模算法改进;Ren等[27]利用构建的证券知识谱实现了财经新闻的有效推荐;李倩玉[28]构建了面向金融实体的行业投资知识谱,为金融从业者分析挖掘投资事件中的投融关系提供了技术支持。上述研究都一定程度上考虑到了证券领域知识谱内在的异构知识关联的特性,并实现了知识谱在股票预测、新闻推荐和行业投资中的具体应用。本文则从投资者的视角出发,将以股票为核心的知识谱应用于相关股票的发现。
股票作为有价证券的重要表现形式之一,被称为一国宏观经济的“温度计”或“晴雨表”。在股票市场中,宏观经济政策、行业发展情况、公司经营情况、交易者期望等诸多内外界因素均会对其产生一定的作用。大量的实证研究表明,股票之间存在相关关系,特别是在行业板块内,股票的价格波动受到其他股票的影响[5-6,29-31]。因此,探索能够反映股票间真正相关关系的方法,对资本估值、投资组合决策和市场风险管理等具有重要价值。传统研究主要运用统计学方法完成个股间的相关性分析,如格兰杰因果检验[32]、相关系数与协方差[33]、Copula[34]等。这些方法仅考虑股价相关信息而忽略了股票所在行业、所属概念及股东间共同持股与关联交易等隐含信息;尤其是我国股市常常还会出现因联动效应而导致股票出现过度相关性[35],仅通过最小二乘、资产定价模型等统计模型计算相关性很可能得到伪相关的结论。随着信息技术的发展和研究范式的变迁,部分学者意识到局部样本分析的局限性,开始从复杂性的角度去分析股票间存在的关联现象,于是数据驱动的复杂网络建模方法得到了广泛的应用。最早将网络模型引入股票市场分析的是Mantegna[36],首次根据股票价格构建了相关股票关联网络,并基于该网络对标普500股票进行了层次聚类分析;而后Lee等[37]构建了韩国KOSPI的200支股票关联网络,通过分析网络的平均路径长度、度分布等统计指标对股票市场的宏观关联特定进行了初步探究。国内学者庄新田等[38]以上交所交易的部分股票为例,建立了股票价格波动相关系数网络,发现该股票网络具有小世界性和明显的无标度性;陈花[39]将社会经济系统视为复杂性系统,构建了中国股票市场间有向复杂网络,并通过分析行业板块和区域板块股票间有向相关性,得出大部分股票具有较强的自相关性的结论。
复杂网络模型通过创建股票的关联拓扑网络,个股表示节点,节点间的连边长短表示相关性强弱[40,41],通过数据实验计算得出股票之间的相互关联关系,然后对所建立的股票市场复杂关联网络进行理论分析,能够较好地为股票市场中的交易实践提供理论支持。然而,从本质上来说,构建的股票关联网络是一种同质网络,其关联关系的计算方式依旧依赖于价格收益相关矩阵的计算结果,而知识谱可以被理解为是一种包含外部关联知识的异构网络,可以通过挖掘实体间的内在关联发现股票内在的关联特征甚至发现潜在的交易风险,从而帮助投资者更好地实现基于关联知识的有效决策。此外,从数据分析与知识挖掘的角度来说,基于知识谱的关联股票发现与分析是典型的第四范式驱动的有效实践,具有严密的科学性。
综上,本文分别进行了思路创新、算法改进与应用扩展。在研究思路与视角方面,引入知识关联的概念,首先利用以股票为核心的外部知识构建多模式知识关联的种子知识谱,而后基于已有谱和对文本的知识抽取进行知识更新与融合,最终构建出知识关联性强、实用性强的金融证券市场知识谱。在构建谱的流程与算法方面,研究在知识抽取子任务中选择FinBERT预训练模型并运用远程监督学习的思想,以降低人工标注的成本和误差。在具体的应用与实践方面,从投资者角度出发,选取相关股票挖掘这一典型应用场景,投资者可以利用这些实体关系实现基于股票数据的有效决策,并获得业务洞察力,更好地预测股票市场。
3金融证券知识谱构建
证券行业知识分散且复杂度高,数据源与数据内容缺乏关联性,相关信息存在形成孤岛的风险,因此需要对多源异构数据进行关系映射、关联融合,才能最大程度地发挥金融大数据的效用。本文借鉴唐旭丽等[42]对金融大数据知识关联模式的分类方式,通过如1所示的金融证券知识谱构建框架,成功将股票相关数据与公告、新闻等文本融合。

1金融证券知识谱构建框架
1数据来源与预处理
本文数据源包含用于搭建股票关联信息的半结构化的股票数据、用于识别和发现更多实体-关系并进行知识扩充的非结构化文本数据。其中,股票数据通过调用tushare接口获得,包含了股票基本数据、概念数据、股东持股数据和价格数据等4个数据集。基本数据集包含了截至2020年11月1日A股上市的4061支股票代码、名称及其所属行业信息;概念数据集主要存放概念股及其炒作的358个热点概念术语信息;股东持股数据集包含A股上市公司前十大股东持有数量和比例信息;价格数据集则存储了A股股票在2019年11月1日-2020年10月31日期间累计242个交易日的开盘价、收盘价和成交量信息。
2基于领域本体的概念层构建
领域知识谱构建主要包括模式层和数据层的构建。其中,模式层主要依赖前期整合的多源异构数据和领域专家的介入,对金融证券知识谱涉及的术语、概念和关系进行抽取与定义,并提供一套知识表示规范框架,以便明确谱的概念边界。
股票市场中涉及的主体和关系具有概念交叉性、关系多样性和时空动态性的特征,因此以股票为核心的金融证券行业本体设计需要综合考虑基本概念关系和动态的社会关系,如持股与控股关系、监管与调控关系、信用与雇佣关系等。研究基于唐旭丽等[42]在金融知识表示中提及的三类本体,复用由美国企业数据管理委员会主导、通过众包方式构建的金融全领域静态实体FIBO[43]中的部分概念和属性以作为分类知识关联的基础;复用社会本体和动态本体中的直接和间接金融社会关系,并强调了发行股票的企业所面临的动态风险。据此设计三种金融关系及其子关系,包括class-of关系、behavior关系和attribute-of关系,以结合金融证券行业的知识特征,在细粒度环境下阐释语义关系。预定义Schema集合如表1所示,通过对概念、属性和关系的语义关联,得到如2所示的RDF。
表1预定义Schema集合
| 上市公司 | 同义 | 股票 |
| 股东 | 持有 | 股票 |
| 机构 | 投资 | 上市公司 |
| 人物 | 投资 | 上市公司 |
| 机构 | 合作 | 机构 |
| 上市公司 | 合作 | 上市公司 |
| 机构 | 合作 | 上市公司 |
| 股票 | 属于 | 概念 |
| 上市公司 | 属于 | 行业 |
| 上市公司 | 发布 | 公告 |
| 上市公司 | 发生 | 事件 |
| 上市公司 | 面临 | 风险 |
| 上市公司 | 位于 | 位置 |
| 上市公司 | 主营 | 产品 |
| 上市公司 | 实控人 | 人物 |
| 人物 | 担任 | 职务 |
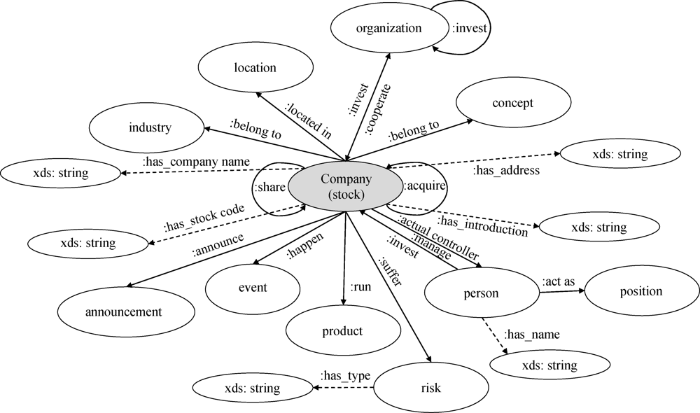
2金融证券行业子领域本体RDF
3面向知识关联的种子知识谱构建
在种子知识谱构建中,基于Snowball的迭代思想进行谱的扩充,以实现小样本环境下的大规模谱构建。可见,基于种子知识谱的迭代是知识的不断关联、融合与迭代的过程。
对于已获得的股票相关数据,各项之间存在较明确的对应关系,根据构建的本体框架定义类的属性和层次,并按照特定的映射规则将部分公司、概念、行业、股东等数据转化为三元组的表示形式,作为表征金融证券行业静态知识的集合,为后续实体识别和关系抽取提供训练样本;对于非结构化的文本信息,则利用人工标注的方法,如从财经新闻、公告和研报中进行面向时空关联和事件关联的企业关系抽取与风险识别,并对风险事件进行抽象描述,而后通过聚类方式扩充训练样本集。
4知识抽取
在知识抽取中,由于金融领域知识具有复杂分散的特点,传统的人工抽取方式效率较低,且依赖于从业人员的经验,不利于大规模的关联分析。随着人工智能的发展,出现了大量的知识抽取算法和工具,如黄胜等[44]提出一种基于文档结构与Bi-LSTM-CRF网络模型的信息抽取方法;安磊[45]则设计了融合多种实体识别模型和关系抽取模型的知识服务抽取系统,并将其部署到Kubemetes集群。本文借鉴上述模型算法,并引入了FinBERT预训练模型,以解决非结构化文本抽取关联知识的问题。
对于面向非结构化数据的知识抽取任务,其核心目标是将非结构化的文本信息转化为结构化或半结构化的“实体-关系-实体”三元组,以便知识存储。作为构建知识谱的核心任务,知识抽取对标注文本的质量和算法模型都有很高的要求。虽然有研究认为传统的Pipeline模式存在误差积累和实体冗余等缺点[46],但是Zhong等[47]研究表明对于实体和关系,相比于联合学习,学习不同的语境表示更加有效,因此独立训练的实体抽取和关系抽取模型仍然是一种简单高效的方法。本文基于上述论证,首先采用序列标注模型预测句子中的实体,然后用关系分类模型判断实体关系的类别,过滤掉关系为未知的情形,最终得到提取的三元组。具体实现流程如3所示。
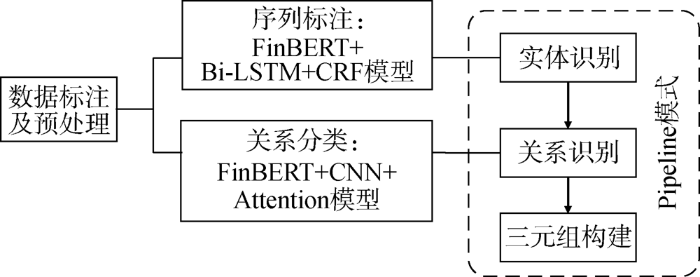
3基于Pipeline模式的知识抽取流程
实体识别
数据标注
将实体识别环节视为一个序列标注问题,首先采用Python+tkinter框架自行编写的标注工具通过BIO标注法对随机抽取的500条上市公司公告、500条研报和1000条金融财经新闻短讯进行人工标注,标注示例如表2所示。之所以没有等比对三类文本进行抽取标注,是因为考虑到采集样本的数量差异和平衡长短文本造成的样本偏差带来的影响。
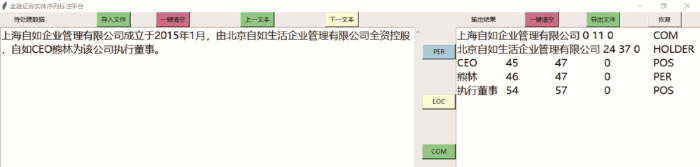
4用于金融证券实体序列标注的自制标注平台
表2基于BIO标注体系的财经新闻文本人工标注示例
| B-COM | I-COM | I-COM | I-COM | I-COM |
| 能 | 源 | 原 | 董 | 事 |
| I-COM | I-COM | O | B-POS | I-POS |
| 长 | 魏 | 银 | 仓 | 股 |
| I-POS | B-PER | I-PER | I-PER | O |
| 权 | 被 | 冻 | 结 | 。 |
| O | O | O | O | O |
训练模型及其参数设置
实验采用FinBERT+Bi-LSTM+CRF实体标注模型进行训练。首先利用FinBERT预训练模型对词向量进行训练,然后将生成词向量通过与定义的实体标签信息进行合并编码,输入Bi-LSTM模型加强词性分析,捕捉前后文的双向语义信息,最后通过CRF解码完成命名实体识别任务。采用CRF的原因是其能对标签的转移状态建模,降低错误标签序列出现的概率,从而增加模型的准确率。整个流程框架如5所示。
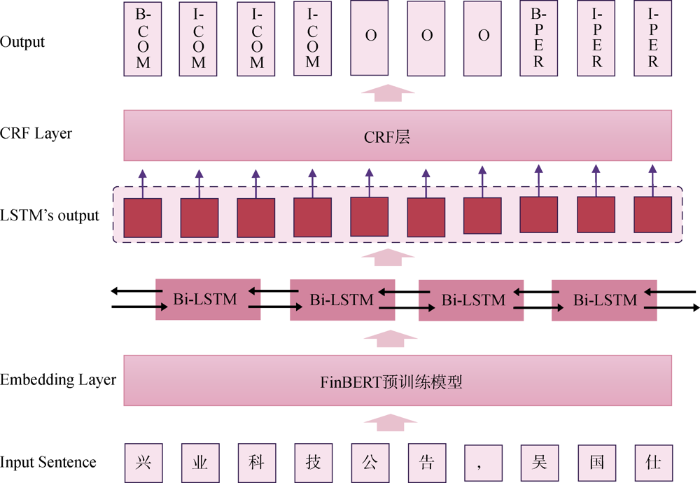
5基于FinBERT+Bi-LSTM+CRF的实体标注模型
在FinBERT+Bi-LSTM+CRF模型中,实验参数设置如表3所示。
表3FinBERT+Bi-LSTM+CRF模型参数
| 输入文本最大长度MAX_SEQ_LEN | 200 |
| Hidden size | 128 |
| Dropout | 0.1 |
| Learning rate | 0.001 |
| Batch size | 8 |
| epoch | 30 |
实验结果
将14644条标注数据按照7:1:2的比例划分为训练集、开发集和测试集,并通过精确率、召回率、F1值、微平均和宏平均等指标对实验结果进行评价。最终的实验结果如表4所示。
表4实体识别实验结果
| PER | 0.801 2 | 0.780 6 | 0.790 8 |
| LOC | 0.884 8 | 0.769 8 | 0.823 3 |
| COM | 0.941 4 | 0.804 1 | 0.867 4 |
| ORG | 0.838 7 | 0.827 3 | 0.833 0 |
| HOLDER | 0.660 2 | 0.625 3 | 0.642 3 |
| INDUSTRY | 0.756 1 | 0.556 9 | 0.641 4 |
| PRODUCT | 0.857 1 | 0.728 6 | 0.787 6 |
| RISK | 0.543 9 | 0.775 0 | 0.639 2 |
| POS | 0.757 3 | 0.667 1 | 0.709 3 |
| 微平均 | 0.848 2 | 0.615 8 | 0.713 6 |
| 宏平均 | 0.782 3 | 0.726 1 | 0.748 2 |
基于上述结果可发现对公司、人物、机构等实体识别精确率、召回率和F1值均较高,而对于股东和风险的识别效果并不是很好,一方面与训练样本集数量较少有关,另一方面则是由于对概念定义范畴不同导致的。
模型训练完毕后,将剩余未标注的8941条语句导入进行实体识别,为保证关系抽取的质量,经过人工去重、消歧和对齐后得到约4万个实体。
关系抽取
数据标注
关系抽取可以被抽象为分类问题,主流方法仍然是依赖于人工标注的监督训练方法。然而,考虑到标注成本的问题,在实体识别的基础上仅随机抽取2000条数据参照预定义Schema进行类别标注,并结合利用半结构化数据构建的种子知识谱采用远程监督学习方法完成训练,整个流程如6所示。
6远程监督关系抽取流程
在标注时,由于单句中可能出现多种关系,如“激智科技同Nanosys合作发力新品,董事长张彦:将拓展医疗、汽车等新业务领域。”就包含了、、、等多个实体关系三元组。因此,对每个候选实体对进行Label标注,得到训练学习所需的正例和负例样本。此外,标注实体对的起始位置,便于模型训练。部分标注结果如表5所示。
表5关系抽取部分标注结果
| 美都能源(600175)卷入九好造假风波 回应称“安排”是中性词 | 面临 | 美都能源 | COM | 0 | 九好造假风波 | RISK | 14 |
| 三聚环保(300072)拟7.7亿港币购巨涛石油服务股权成为其控股股东 | 持股 | 三聚环保 | COM | 0 | 巨涛石油 | COM | 20 |
| 水泥建材走高,华新水泥(600801)涨停 | 属于 | 华新水泥 | COM | 7 | 水泥建材 | INDUSTRY | 0 |
| 吴长江所持德豪润达(002005)股份开拍 两笔标的各有一人报名 | 持股 | 吴长江 | PER | 0 | 德豪润达 | COM | 5 |
| 鲁阳节能(002088):陶瓷纤维产品销量提升业绩预增超1倍 | 主营 | 鲁阳节能 | COM | 0 | 陶瓷纤维产品 | PRODUCT | 13 |
远程监督与多示例学习
远程监督是将已有知识库对应到丰富的非结构化数据中生成大量的训练数据,从而训练出一个效果不错的关系抽取器[49]。具体来说,在训练阶段,首先把训练语料库中句子的实体识别出来,如果多个句子包含两个特定实体,而且这两个实体是种子知识谱中的实体对,那么基于远程监督的假设,这些句子都表达了这种关系,于是从这几个句子中提取文本特征,拼接成一个向量,作为这种关系的一个样本的特征向量,用于训练分类器。
远程监督算法是目前主流的关系抽取系统广泛采用的方法。然而,远程监督假设过于强烈,易标注错误,从而引入大量噪声数据。因此,本文采用PCNN+Attention模型[50]进行训练,该模型是一种多示例学习方法,选取每包中预测类别最接近真实类别的一个实例作为包的输出,使用一个能代表实体间关系的向量和包中的句子实例求相似度,得到一个权重参数,对不同的实例分配以不同的权重再求和,并通过注意力的方式减小噪声数据的影响。其中,特征提取是非常重要的一个环节,涉及对文本特征、实体相对位置特征等的编码与提取,其编码过程如7所示。

7PCNN特征提取编码
参数配置
PCNN+Attention模型中的参数设置如表6所示。其中,Balancerate是为了平衡类别设置的。
表6PCNN+Attention模型参数
| 输入文本最大长度MAX_SEQ_LEN | 200 |
| Word embedding | 100 |
| Tag embedding | 20 |
| Pos embedding | 10 |
| Dropout | 0.5 |
| Learning rate | 0.001 |
| Balance rate | 0.5 |
| Batch size | 64 |
| epoch | 30 |
④实验结果
利用给定的金融新闻和公告测试集对抽取效果进行测评,选取精确率、召回率和F1值作为测评指标,结果如表7所示。由于class-of关系在利用半结构化数据构建种子知识谱中已进行了规范抽取,因此未在本实验中涉及。
表7关系分类实验结果
| symmetric | Synonymous(SYN) | 0.79 | 0.74 | 0.76 |
| behavior | Hold(HOL) | 0.63 | 0.66 | 0.64 |
| Invest(INV) | 0.75 | 0.70 | 0.72 | |
| Cooperation(COO) | 0.69 | 0.71 | 0.70 | |
| Announce(ANN) | 0.51 | 0.45 | 0.48 | |
| Suffer(SUF) | 0.65 | 0.69 | 0.67 | |
| attribute_of | Located_in(LIN) | 0.78 | 0.77 | 0.77 |
| Run(RUN) | 0.59 | 0.54 | 0.56 | |
| Act_as(ACT) | 0.80 | 0.67 | 0.73 |
由上述结果可以看到,基于远程监督学习的关系抽取整体上取得了比较不错的效果,但发布公告、面临风险、主营产品等行为和属性关系的精确率和召回率都较低。一方面是因为训练样本标注关系的样本数量不均衡导致拟合效果较差;另一方面则是受实体识别结果的影响,如风险、产品等实体F1值较低,其属性关系自然也较低,这在一定程度上证实了Pipeline关系抽取的误差积累效应。
4知识融合
本文在知识抽取的工作基础上采用距离度量的方法进行实体对齐,并进一步通过人工核验剔除错误对齐项。同时,通过增强种子谱的不断迭代,最后完成大规模知识的加工与融合,构建的实体、关系类型和数量如表8和表9所示。
表8知识谱实体类型汇总
| StockName | A股股票名称 | 4 061 | 平安银行;中信证券;贵州茅台 |
| Company | A股上市公司 | 3 949 | 平安银行;中信证券;贵州茅台 |
| Concept | 概念 | 363 | 5G概念;区块链;新型病毒 |
| Holder | 股东(机构或个人) | 8 433 | 中国平安人寿保险股份有限公司;郭训平 |
| Industry | 公司所隶属的行业 | 110 | 通信服务;互联网;半导体 |
| Organization | 组织机构 | 124 | 深交所;保监会 |
| Person | 人物 | 8 424 | 付红玲;陈曦 |
| Position | 职务 | 1 070 | 董事长;工信部部长;创始人 |
| Risk | 风险 | 330 | 股权冻结 |
| Location | 位置 | 67 | 江苏;华中地区 |
| Notice | 公告 | 60 702 | 振德医疗用品股份有限公司关于实施“振德转债”赎回暨摘牌 |
| Product | 产品 | 24 212 | 经济贸易咨询;代理进出口 |
| Total | 总计 | 111 845 | 约11.2万实体量级 |
表9知识谱关系类型汇总
| ConceptInvolved | 所属概念 | 18 943 | <亚光科技,属于,密集调研> |
| IndustryInvolved | 所属行业 | 22 238 | <上海医药,属于,医药商业> |
| StockTypeIs | 股票成分 | 8 230 | <三全食品,成分股属于,深股通> |
| ChairmanIs | 法人代表 | 5 467 | <科恒股份,法人代表,付红玲> |
| AnnouncementIs | 发布公告 | 60 702 | <平安银行,发布公告,关于公开…> |
| ShareHolding | 持股 | 13 239 | <中国证券金融股份有限公司,持有,平安银行> |
| IsControlledBy | 实际控制人 | 910 | <四环生物,实控人,陆克平> |
| ManagerIs | 总经理 | 6 223 | <科恒股份,总经理,蔡承儒> |
| MainBusinessIs | 主营产品 | 24 212 | <丽人丽妆,主营,香水化妆护肤…> |
| Located_in | 位于(省份/城市) | 166 | <天风证券,位于,湖北> |
| Invest | 投资 | 1 760 | <交通银行,投资,东风公司> |
| Coopration | 合作 | 224 | <中国电信,合作,科大讯飞> |
| Suffer | 面临风险 | 1 056 | <豫铁投债,面临,暂停上市> |
| Total | 总计 | 163 370 | 约16.3万关系 |
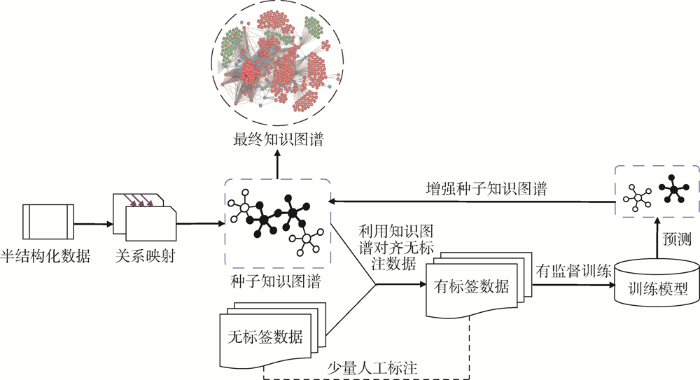
经过上述对数据的预处理和知识建模、抽取、融合等关键步骤,最终将实体关系对导入数据库Neo4j中进行知识存储,得到如8所示的以股票为核心的金融证券知识谱。通过可视化的展示可以直观地发现金融证券关联知识,同时更加便捷地查询不同实体间的直接与间接关系。
8基于Neo4j的金融证券知识谱
4基于知识谱的相关股票发现
为了更好地发掘股票之间的隐性关联,研究基于前文已构建的具有多实体和关系的证券知识谱,采用挖掘算法探寻和推理相关关系,并通过统计学方法进行检验,以期发现股票市场的潜在特征,帮助投资者理性决策。
1亲密度与相似度计算
数据库擅长分析异构数据点之间的关系,而其中的核心就是链路预测算法。早在2003年,Adamic和Adar在研究社交网络的预测问题时提出了AdamicAdar算法[51]。该算法是一种基于节点间共同邻居的亲密度测算的数据挖掘算法,通常亲密程度越大的节点之间的亲密值会越高。AA指标不仅考虑了共同邻居的度信息,还根据共同邻居的节点的度给每个节点赋予一个权重,然后把每个节点的所有共同邻居的权重值相加,其和作为该节点对的相似度值。亲密度的计算方法如公式所示。
A=∑u∈N∩N1log|N|A=∑u∈N∩N1log|N|
其中,NN为与节点uu相邻的节点集合。
由此可见,每对节点的分数可看作为基于拓扑网络的“近似度”,两个节点越相近,它们之间存在联系的可能性就越大。在上文构建的金融证券知识谱中,虽然股票与股票间没有直接相连的节点,但是它们通过行业、概念、股东等间接关联,因此利用该算法预测联系紧密的股票具有可行性。
通过计算,发现了若干关联股票对,选取亲密度最高的10支关联股票对,如表10所示。
表10基于链路预测算法的Top10相关股票列表
| 东北证券 | 广发证券 | 0.820 755 |
| ST长投 | 畅联股份 | 0.818 182 |
| 东北证券 | 长江证券 | 0.760 000 |
| 津滨发展 | 天房发展 | 0.750 000 |
| 中山公用 | 广发证券 | 0.747 967 |
| 河钢股份 | 新兴铸管 | 0.741 935 |
| 中山公用 | 东北证券 | 0.719 008 |
| 陕国投A | 广发证券 | 0.716 535 |
| 中国石化 | 中国石油 | 0.714 286 |
| 中国铁建 | 中国中铁 | 0.714 286 |
对应的Cypher语句如下所示。
RETURNgds.util.asNode.股票名称ascharacter1,gds.util.asNode.股票名称ascharacter2,intimacy
除了计算亲密度,可以利用嵌入直接计算股票间的相似度。根据MarkoWitz理论[52],股票之间相似性越高,投资组合有效性就越低,它们代表的股市系统性风险就相对越大。对此,挖掘关联股票一方面可以帮助避免对相似股票对进行组合投资,从而达到分散风险的目的;另一方面,相似性导致的联动效应可以帮助结合基本面和技术面预测股价走势,在特定行情下可以根据股票1走势判断股票2行情,从而实现套利。
本文基于已有谱利用Node2Vec算法进行节点采样,并使用节点向量嵌入表示股票;然后根据得到的股票节点嵌入向量S1S1和S2S2,可以计算它们之间的余弦相似度,如公式所示。
cos=e1⋅ee⋅|e=∑dj=1∑dj=12√×∑dj=12√cos=e1·ee·|e=∑j=1d∑j=1d2×∑j=1d2
其中,e1e1和e2e2为股票的嵌入向量表示,因此有e1=fe1=f和e2=fe2=f;dd为嵌入的维数。
实验设置EmbeddingDimension为60,迭代150次,并设置随机游走的窗口长度为将“东北证券”作为目标股票,通过如下的Cypher语句可以得到按降序排列的相关股票,其中Top10如表11所示。
,
reduce-|Sum+stvec[i]*stvec[i])asS,
ABS)ASsimilarity,st股票名称,st‘TS代码’
表11基于余弦相似度算法的Top10相关股票
| 0.999 241 | 陕国投A | 000563.SZ |
| 0.998 753 | 申万宏源 | 000166.SZ |
| 0.998 712 | 长江证券 | 000783.SZ |
| 0.998 681 | 中山公用 | 000685.SZ |
| 0.998 416 | 广发证券 | 000776.SZ |
| 0.998 134 | 吉林敖东 | 000623.SZ |
| 0.955 101 | 四环生物 | 000518.SZ |
| 0.953 625 | 中金岭南 | 000060.SZ |
| 0.953 002 | 柳工 | 000528.SZ |
| 0.952 224 | 山推股份 | 000680.SZ |
从表10和表11中可以发现,亲密度算法倾向于将行业相近、业务相仿的股票对作为输出,但利用余弦相似度得出的高相似度股票却不一定仅属于相近行业或概念,如“吉林敖东”属于医药制造行业而非证券业。这表明股票相关性与行业可能具有紧密的联系,但同时还受多种因素影响;跨行业相关的股票对可以为投资者组合投资提供更多的可能。
上述结果对投资者进行配对交易也有重要帮助和新的启示。配对交易是基于统计套利的一种市场中性策略,传统的配对交易多半从市场上找出历史股价走势相近的股票进行配对,且配对交易股票池选择为按行业划分,这样会遗漏大量跨行业相关股票的有效配对机会[53]。而基于知识谱的链路预测算法将与股票关联的行业、股东、概念、产品等信息都考虑在内,还可以挖掘多股票的关联配对交易策略,结果置信度更高。
2收益相关性检验与分析
在以往的研究中,“相关股票”多指股票收益率的相关程度[54],因此通过计算股价对数收益,并利用时间序列间的协方差、Pearson相关系数衡量股票间的线性关系,以此与基于知识谱得出的相关股票进行对比。
研究选取“东北证券”及其余弦相似度最高的股票作为样本,首先利用公式计算11支股票的连续对数收益,然后通过公式计算出它们的Pearson相关系数,并得到如9所示的相关系数热力矩阵。其中,ci,t+1ci,t+1表示当日收盘价,ci,tci,t表示上一交易日收盘价;R̅i和R̅jR̅i和R̅j分别表示股票ii和股票jj的平均收益率,dd表示交易天数。
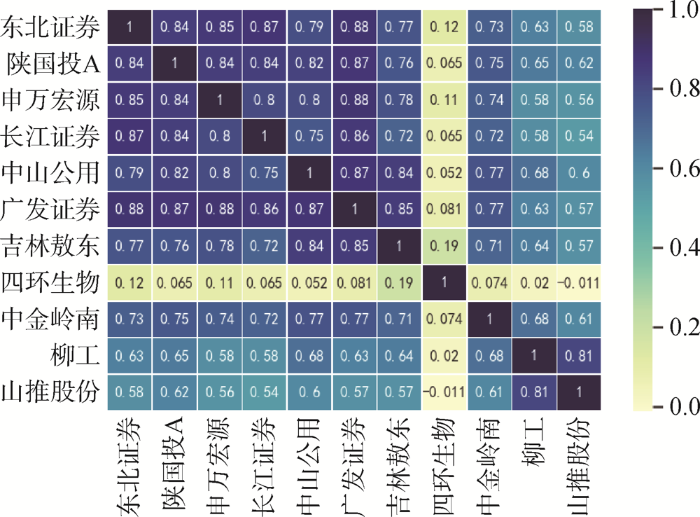
9股票相关系数热力矩阵
进一步地,通过如10所示的11支股票在2019年11月30日-2020年10月31日期间的股价走势可以看到这些股票的股价走势大体一致,具有一定的协整性,这证实了基于知识谱得到的关联股票在股票收益及波动性上的强相关性。
10
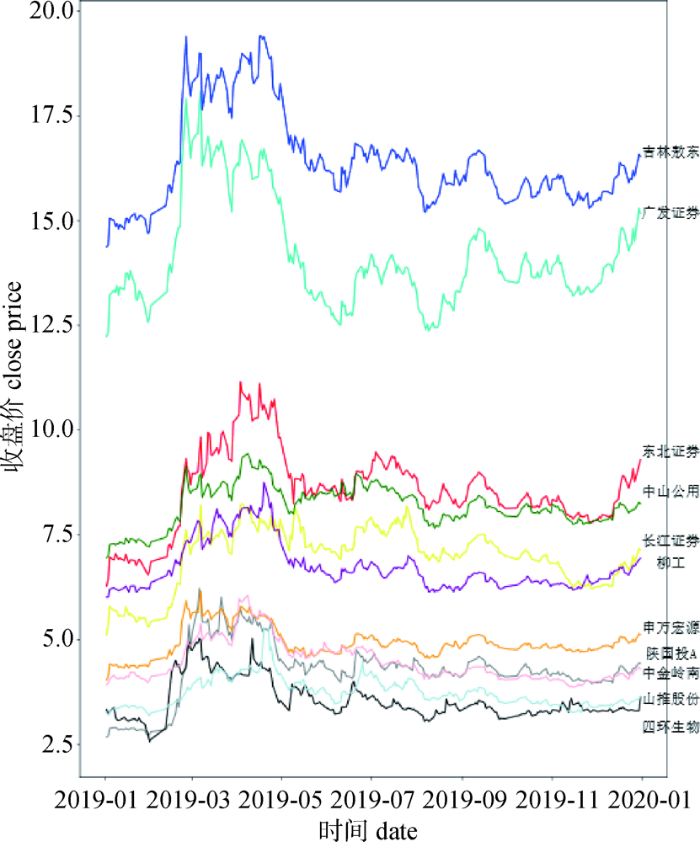
10相关股票股价走势
Ri,t=lnci,t+1ci,t,i=1,2,…,m,t=1,2,…,dRi,t=lnci,t+1ci,t,i=1,2,…,m,t=1,2,…,d
Pi,j=∑dt=1∑dt=122⎷Pi,j=∑t=1d∑t=1d22
然而,通过观察可以发现,“四环生物”与其他股票的相关性却很低。为分析这一现象,查询已有知识谱后发现,“四环生物”与其他证券行业的股票虽然在产业链上的相关性并不明显,但该公司曾与申万宏源、广发证券等多家证券公司签署过股份认购合同,并被多家证券公司频繁买入卖出,其实控人陆克平也与多家公司存在股权关联,并与一些重要的股东构成一致行动人,因此与其他几支目标股票的关联路径较为相近,如11所示。
11
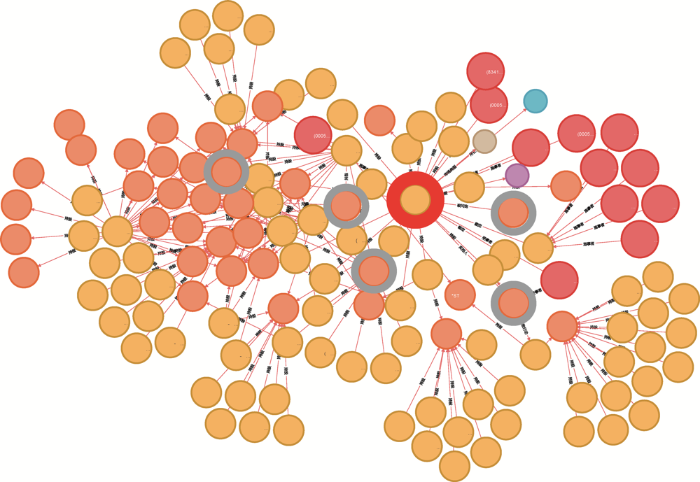
11“四环生物”与关联目标股票
事实上,通过事件知识关联查询还可以发现,证监会也曾通过调查发现陆克平隐秘“操控”这支股票,“四环生物”作为“A股第一支被暂停上市的股票”,与其背后动荡且分散的股权结构和纷乱的投资操作相关。此外,在证监会事先告知书前,“四环生物”的股东中就一直隐现一股“阳光系”势力,而这也导致“四环生物”多次出现股东“对垒”、经营决策无法通过的情形。可见,基于知识谱不仅可以发现价格关联的相关股票,还能够体现背后的关联机理,尤其是对于发行股票的公司之间存在绝对控股、关联交易、风险关联等隐性知识和现象的揭示,既可以帮助从业人员进行更有针对性的投研分析和风险管理,对于一些初级投资者,也可以帮助他们了解更多公司股权结构及经营的内幕信息,及时规避风险。
上述案例分析结果充分表明,股票市场的股价波动具有随机性,股票间的相关关系不仅体现在简单的线性相关方面,由于受多重因素影响,股票之间可能存在潜在的非线性相关关系,需要通过多种知识关联模式将各影响因素关联融合,才能充分挖掘股票相关的机理。本文实证研究表明,将相关系数转化为基于结构的向量嵌入用以测量股票间的相关性更具有优势,通过挖掘潜在的持股控股、关联交易、一致行动人等关联知识,在增强了研究科学性、全面性的基础上能够给投资者带来更多深层次的有效信息,从而为投资决策提供了新思路。
5结语
面对证券行业数据爆炸但组织和利用效率低下的现状,本文利用多源异构的新闻、公告等数据,首先利用多知识关联模式搭建了以股票为核心的种子知识谱,而后在深度学习的基础上,利用FinBERT+Bi-LSTM+CRF模型对标注的数据集进行实体识别,并通过远程监督的方法实现了关系的有效抽取,从而成功将分散的领域知识进行融合,最终构建出具有约12万个实体和13万个关系的金融证券知识谱;进一步地,利用已有知识谱对相关股票进行挖掘,从投资者的角度体现了知识谱在股票发现和投资策略方面的应用价值。
本文在知识谱的构建和应用方面都实现了初步的实践,但也存在一些不足之处。例如,在构建知识谱的关系抽取环节中,预定义Schema无法很好地界定持股与控股关系、对于子母公司关系未进行有效抽取等,而且预定义关系较难满足当前呈爆发状态增长的信息抽取任务要求。此外,股市的变化受多种因素影响,本文构建的以股票数据为核心的金融证券知识谱仅考虑了所属行业、股东持股和金融风险等领域相关知识对股票相关性的影响,对于舆情数据的细粒度抽取和深度挖掘不够。
未来将在保证知识谱的规范性、可扩展性和可复用性的基础上,基于已获取的新闻、公告等舆情知识,通过构建金融时序事件谱并融合现有的证券行业知识谱,建立起各类知识与股票的关系,并通过动态信息的演化和风险路径传导综合分析股票的关联和未来可能的走势,以期帮助投资者完成真正的“智能选股”与“智能决策”。
文章为作者独立观点,不代表股票交易接口观点

股民评论